BASIC (Re)Numbering — with Commodore
How to thoroughly renumber Commodore BASIC programs (PET 2001, VIC-20, C64)

Renumbering a is popular beginner’s sport for those who dare to venture into the mythical realms of intricacy, which the BASIC interpreter and its storage formats provide. Since it is also a useful utility, there are numerous programs for this, especially it’s a favorite example in the intructory sections of machine language guides. However, as always, there’s an easy way and a thorough one. And we’ll see soon, why this may be.
Let’s start at the beginning, a stored BASIC program in memory.
BASIC Code Representation in Memory
We already had a closer look at how Commodore BASIC stores its programs in a previous episode, however, we may want to recap this here with a somewhat different focus. Importantly, Commodore BASIC stores keywords as single-byte tokens, by this saving quite an amount of memory, but there are also literals reppresented in plain ASCII (or, beyond charter code 127, in PETSCII). And, as we shall see, BASIC lines are stored as a linked list and may be all over the place, regardless of their order in sequence.
Trivia: The tokens are the same for the PET 2001, VIC-20, and the C64. However, the first ROM edition for the PET 2001 is lacking the bare GO keyword, which was only added as the very last token in revision 2 of the PET’s ROMs (see below).
Let’s have a look at a (very) simple program:
10 PRINT "NUMBER";:INPUT A 20 PRINT "YOUR NUMBER IS ";A 30 IF A>0 GOTO 10 40 END
As the attentive reader may have observed already, this tiny program is asking for a number (line 10), which is then printed onto the screen (line 20). If the number is larger than 0, we jump back to the beginning, otherwise, we finish on a quite luxurious END statement in line 40.
And this is, what this program looks in memory, in all the glory of its idle bytes. Here, on a PET, where BASIC memory starts at $0401 (on a C64, it’s $0801, and on a VIC-20 it starts at $1000, or, if there’s a memory extension of at least 8K, at $1200):
0400: 00 15 04 0A 00 99 20 22 ...... " 0408: 4E 55 4D 42 45 52 22 3B NUMBER"; 0410: 3A 85 20 41 00 2F 04 14 :. A.... 0418: 00 99 20 22 59 4F 55 52 .. "YOUR 0420: 20 4E 55 4D 42 45 52 20 NUMBER 0428: 49 53 20 22 3B 41 00 3E IS ";A.. 0430: 04 1E 00 8B 20 41 B1 30 .... A>0 0438: 20 89 20 31 30 00 44 04 . 10... 0440: 28 00 80 00 00 00 ......
At first glance, we may already spot some dispersed sequences of ASCII codes, however, the line numbers, we’re particularly interested in, are hiding somewhere in those bytes. Except, for a single “10” standing out near the end of the program, which might be well the jump target of our GOTO command.
Let’s apply a bit more structure to this and find out, how this works:
‘10 PRINT "NUMBER";:INPUT A’ 0401: 15 04 binary address of next line (LO-byte, HI-byte), $0415 0403: 0A 00 BASIC line number as binary (LO-byte, HI-byte), $000A = 10 0405: 99 BASIC token for PRINT (a token’s value is always ≥ $80) 0406: 20 ASCII character <blank> 0407: 22 4E 55 4D 42 45 52 22 ASCII sequence (string literal), "NUMBER" 040F: 3B ASCII character ; 0410: 3A ASCII character : 0411: 85 BASIC token for INPUT 0412: 20 ASCII character <blank> 0413: 41 ASCII character A (identifier) 0414: 00 END OF LINE marker (binary zero)
As we may see, almost everything is stored as ASCII text with the notable exception of the tokens, which substitute the BASIC keywords. A token has always the highest bit set and a value ≥ $80. From this follows that any normal ASCII text, outside of string literals, must not have the MSB set, hence, PETSCII special characters are not allowed in normal code.
The most interesting parts, however, are the first 4 bytes and the very last one, which provide the structural aspect to the code: The first pair (in LO-HI order) provides a link to the memory address of the next line in sequence, the second pair the line number in binary. (While this would facilitate line numbers up to 65535 in theory, the highest line number supported by Commodore BASIC is actually 63999.) A trailing zero-byte eventually ends the line of BASIC code.
‘20 PRINT "YOUR NUMBER IS ";A’ 4015: 2F 04 link to next line, $042F 4017: 14 00 line number (binary), $0014 = 20 4019: 99 BASIC token PRINT 041A: 20 ASCII character <blank> 041B: 22 59 4F 55 52 20 4E 55 4D 42 45 52 20 49 53 20 22 string literal (ASCII), "YOUR NUMBER IS " 042C: 3B ASCII character ; 042D: 41 ASCII character A (identifier) 042E: 00 END OF LINE marker (binary zero)
This is quite the same, but we may verify that the link address of the first line does actually point to the start of this line. For the next line, as we're already familiar with the pattern, we skip a few bytes and are concerned only with the interesting part:
‘30 IF A>0 GOTO 10’ 042F: 3E 04 link to next line, $043E 0431: 1E 00 line number (binary), $001E = 30 ... 0439: 89 BASIC token GOTO 043A: 20 ASCII character <blank> 043B: 31 30 ASCII sequence ‘10’ (line number) 043D: 00 END OF LINE marker (binary zero)
As we can see, while line numbers are generally stored as binaries, when they occur as a jump target in BASIC text, they are stored as plain ASCII strings!
‘40 END’ 043E: 44 04 link to next line, $0444 0440: 28 00 line number (binary), $0028 = 40 0442: 80 BASIC token END 0443: 00 END OF LINE marker (binary zero) 0444: 00 00 line link 0000 => end of code
And here’s our very last line. What’s interesting here, is that it is not the END keyword, which ends the code in memory, this one rather instructs the interpreter to end its execution. What really marks the end of the code, is an empty (zero) line link, which marks the end of the linked list of BASIC lines. This is essential to the housekeeping of the BASIC interpreter. Without, we may encounter some difficulties, when we try to add, insert or edit a line.
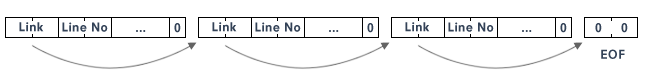
Renumbering
As you probably have worked out already, a simple renumbering algorithm is as simple as following the line links, starting from the BASIC start address (here, on a PET 2001: $0401) and fixing the binary line numbers, LO-byte first, followed by the HI-byte. This is also what most of the tutorial aplications do. However, this is a bit of a naïve approach, because we would probably end up with a nonfunctional program, since the jump targets were left untouched. By leaving this to the user, our utility wouldn’t do a particularly great job.
Identifying Jump Targets
As we’ve seen above, line numbers as jump targets are stored as ASCII literals in the program text. These are quite easy to identify, since they may be preceded by just a few keywords. Namely, these are:
89 ....... GOTO8D ....... GOSUBA7 ....... THENCB A4 .... GO TO
All of them come with a few of special cases:
GOTOandGOSUBmay be part of a “ON … GOTO” or “ON … GOSUB” clause, where they may be followed not only by a single line number, but by a comma separated list of line numbers.
(However, instead of checking for theONtoken and parsing an arbitrary expression inbetween, we may check for a following comma, as well, by this reducing the amount of look ahead or look behind. If an unconditional jump is followed by a list of line numbers, the interpreter will take the jump on the first number and will not care for any following code. Maybe, a construct like this was intended by the user as an alternative, now defunced target, just like commenting a previous target by insertingREM, so it wouldn’t hurt to fix this, as well.)THENmay be followed immediately by a line number, thus indicating a conditional jump, but there’s no obligation for a line number to follow this keyword. Hence, any parsing must be context sensitive.- Finally, “
GO TO” is an alternative form ofGOTO. TheGOkeyword (token$CB) is lacking in the early PET 2001, as it was introduced only with ROM 2.0. The “TO” (token$A4) is the same token as in “FROM A=0 TO 10”. This will require a bit of look ahead. Notably, it maybe following anON, like the more conventionalGOTO, so the same rules apply for this as well. Regarding PETs with ROM 1.0, we won’t have to apply any special care, since the token was added to the end of the list and will simply not occur in those programs.
As always, where there can occur a space character, there may be any number of them, as is the case for the white space which goes between “GO” and “TO”.
Line Numbers as Jump Targets
As previously observed, line numbers are stored as plain ASCCI strings. However, there’s more to them. They may not only be proceded by any number of spaces, they may also contain any number of spaces, which will be simply ignored by the interpreter.
1 0 0 = 100
Here are a few examples of the type of code, we'll have to consider:
GOTO100 GOTO 100 GOTO 1 200 GO TO100 GO TO 100 GO TO 1 200 GOSUB200 GOSUB 200 ON … GOTO 100,200, 300 ON … GO TO 100,200, 300 ON … GOSUB 100,200, 300 THEN100 THEN 100 THEN 1 0 0
And, above all, we must ignore anything following a REM statement and any string literals (in quotes, ASCII $22). Any numbers, we may find here, regardless of the PETSCII character by which they might be preceded, are to be left as-is.
Varying Extent — Code Length
As may have become obvious by these explanations, there’s no guarantee that a new line number may be fitted in the same amount of bytes as there has been previously. E.g., as we have to replace “10” by “1000”, there’s no hope to summon the extra bytes from a miraculous source. We'll have to move all consecutive bytes in memory and we'll have to relink the lines. In essence, we'll have to rebuild the very structure of the program in memory. (However, if there are a few dead bytes in memory from previous edits, we may close these gaps and save a few bytes, as we rebuild the entire linked list in sequence.)
Doing it
Time to come up with an algorithm. Here, for illustration purpose and because it’s also real code for a real emulator, we’ll do it in JavaScript. This shouldn’t only be easier to follow than machine code, at the same time, it also provides us with ample external resources. If we did the same in 6502 code, we’d probably have to move stuff around using buffers, namely the the BASIC input buffer and the cassette buffer(s).
Trivia: Amazingly, the PET 2001 had two cassette buffers, one for the internal tape drive and one for a second, external cassette port. This way, you could compute like a pro, loading both from a dedicated program tape and a data tape without DJ-ing multiple cassettes on a single drive. Which may have been actually of use, when running complex business logic on a machine with just 8K, which may require the sequential loading of partial programs or even code overlays.
Anyway, which way we ever decide to do it, we won’t succeed on a single pass. We’ll have to read all occuring line numbers first and build a reference to the new, renumbered ones in a table. This is particularly, because there may be forward references in the code and there’s no guarantee that jumps will happen only to lines, which we have encountered and renumbered already. So we’ll have to take a second pass to correlate the jump targets according to this reference table, once we’ve successfully parsed all lines in a first pass.
There are aspects, which are open to the implementation. E.g., we could insert the binary line numbers on the first pass, or we could do so on the second pass just the same. If we did it in machine language, we would want to keep at least one of the passes as simple as possible and just skim through the linked list of lines to build the reference table as quickly as possible.
Here, in the case of our external JS utility, we decide to go for a different approach, first parsing and splitting the lines in chunks, which will be either opaque blobs of bytes, for which we do not care, or numbers representing jump targets. We’ll collect them in a list, and then, in a second pass, we’re going to reassemble the code from this list, which is as trivial as rejoining the junks, now using the new numbers for any jump targets, preceded by the new line numbers in binary. And we’ll have to fix up the line link as soon as we know the extent of our newly assembled line. Finally, we’ll add two zero bytes for the end-of-code marker and are done.
(For a machine language implementation, we’d probably move chunks of code into a buffer, parse and reassemble the new code from there into memory, at the same time taking care for any code that has to be moved in order to provide space.)
Let’s dive into this!
First Pass – Parse & Split
For the purpose of this blog, we’ll assume that we have santized our input values already, which will be passed as arguments to our utility function. These are:
- a memory image of our RAM, an array of bytes
- the start address of BASIC in the RAM (for a PET
$0401) - an integer number in the range of 0..36999 as the starting line number
- a non-zero integer as the step number
Further, there will be variables for the array of lines, containing anything, we’ll parse in this first pass, and a table holding a reference of line numbers (old → new). And we’ll encapsulate each of the passes in its own function. This gives us the following basic structure:
// renumber BASIC in provided memory slice (0..max)
// processes GOTO, GOSUB, GO TO, ON GOTO|GOSUB|GO TO, THEN
function renumberBasic(mem, basicStart, startNo, step) {
var lineNoTable = {},
lines = [],
maxLineNo = 36999;
// parse and split lines to chunks of blobs and line targets
// stores parsed chunks in array lines,
// generates a reference of old and new line numbers in lineNoTable.
function parseSplit() {
...
}
// reassamble BASIC code from line chunks using new line numbers
// from lineNoTable
function reassembleLines() {
...
}
parseSplit();
reassembleLines();
}
As for our function parseSplit(), we’ll have a main loop, which will be also safeguarding the range, in case we’d be dealing with corrupted code. In this, we’ll read lines in sequence from memory following the line links. An empty line link will indicated that we have arrived at the end of the code and are done with the pass. Otherwise, we generate a new entry for the line, both in our array of lines and in the reference table “lineNoTable”. Each entry to the lines array will have the original line number and an array to hold the parsed chunks. After advancing the line number in preparation of a new line to parse, we read the rest of the line until we encounter a zero-byte as the EOL marker.
function parseSplit() {
var addr = basicStart,
lineNo = startNo,
maxMem = mem.length,
chunks,
blob;
while (addr < maxMem) {
var lineLink = mem[addr++] + (mem[addr++]<<8);
if (!lineLink) break;
chunks = [];
blob = [];
var ln = String(mem[addr++] + (mem[addr++]<<8)),
byte = mem[addr++],
line = {
'ln': ln,
'chunks': chunks
};
lineNoTable[ln] = lineNo;
lineNo += step;
while (byte) {
...
b = mem[addr++];
}
if (blob.length) chunks.push({'type': 'blob', 'val': blob});
lines.push(line);
addr = lineLink;
}
}
The array blob holds a reference to our current working blob and is initially empty, however, it will be filled in our inner “while” loop, where we’re searching for any jump targets.
while (byte) {
blob.push(byte);
switch(byte) {
case 0x8F: // REM (read rest of line)
while (mem[addr]) blob.push(mem[addr++]);
break;
case 0x22: // quote (read up to next quote)
var c = mem[addr++];
while (c) {
blob.push(c);
if (c === 0x22) break;
c = mem[addr++];
}
break;
case 0x89: // GOTO
case 0x8D: // GOSUB
parseLineTarget(true);
break;
case 0xA7: // THEN
parseLineTarget(false);
break;
case 0xCB: // GO (read ahead and test for TO)
var t = addr;
while (mem[t] == 0x20) t++; // skip any blanks
if (mem[t] !== 0xA4) break;
while (addr <= t) blob.push(mem[addr++]);
parseLineTarget(true);
break;
}
byte = mem[addr++];
}
Here, we first add the byte just read to our current blob. Then, we check, if it is a token of interest in a switch statement:
- If it is a REM statement, we’ll have to add any following bytes to the blob, without further processing, until the end of line.
- Quite the same, we add any string literals, as started by a double quote (
$22), as-is. The only substantial difference here is that we’re looking for the next quote ($22) instead of the EOL mark. - If we encounter a token for
GOTO($89) orGOSUB($8D), we pass on to a function “parseLineTarget()” to do the actual job of scanning for and extracting the target line number. The argument “true” passed to this function indicates that this may be a list (as used for “ON … GOTO”, etc). - The same is true for
THEN($A7), but this may be not a list (as indicated by the argumentfalsepassed to the “parseLineTarget()” function).
Note that this is quite a luxury, since, regarding valid BASIC syntax, it wouldn’t matter, if we were scanning here for a list, as well. - Finally, we handle
GO($CB), which is a different kind of beast, since we’re going to handle this conditionally only. Therefore, we’re scanning ahead. If the next non-blank byte is not a token forTO($A4), webreakout of the switch statement. Only, if we did find this token, we’ll copy any of the bytes already scanned to the blob and call our function “parseLineTarget()” to do the rest.
So, the real business of identifying line numbers and splitting the source is left to a function “parseLineTarget()”, which is a function internal (and private) to “parseSplit()”, looking like this:
// scans for a jump target,
// generates a target entry and a new blob in current chunks,
// any leading blanks are added to the current blob
function parseLineTarget(maybeList) {
while (mem[addr] === 0x20) {
blob.push(0x20);
addr++;
}
// parse ASCII to string, ignoring any blanks
var n = '',
c = mem[addr];
while ((c >= 0x30 && c <= 0x39) || c === 0x20) {
if (c !== 0x20) n += String.fromCharCode(c);
c = mem[++addr];
}
// if we found a number, push chunks and open a new blob
if (n !== '') {
chunks.push({'type': 'blob', 'val': blob});
chunks.push({'type': 'target', 'val': n});
blob = [];
// scan for any comma (ON GOTO|GOSUB|GO TO)
if (maybeList && c === 0x2C) {
blob.push(0x2C);
addr++;
parseLineTarget(true);
}
}
}
While this function does much of the heavy lifting, it is also quite straight forward:
- First, we consume any white space and add it to the current working blob. (For a
THEN, which is not followed by a line target, this won’t hurt any way.) Since we’re looking explicitly for blanks ($22), we won’t have to worry about any EOL, as well. - The next thing should be a line number providing the jump target. This one should start with a numeric character (
$30..$39). We collect any numeric characters in a string, ignoring any blanks in the process, by this also normalizing the representation. - If our string in variable
nisn’t empty, we actually found a line number. In this case, we close the current working blob by adding it to the list ofchunksin our currentline. Then, we add a new item containing the target line number. Finally, we create a new workingblobfor any bytes that may follow. - By this, we’re nearly done. But there may be an entire list to be processed, as incicated by the boolean flag
maybeList, which has been passed to the function as an argument. If this istrueand the current character, which was the first non-numeric and non-blank character scanned by our number collection loop, happens to be a comma ($2C), we repeat the process in a tail recursion, in order to scan and parse the next target.
I guess, the algorithm lends itself rather well to 6502 machine language code, as well, if we replaced the store-in-chunks mechanism by some actual copying to current pointer positions in memory. However, on the 6502, we’d probably prefer to do this on the second pass. Using a higher level language with ample resources at hand, we prefer to divide the tasks along the lines of gathering and preparing information on the one hand and final (re)assembly on the other hand.
By this, we have our entire parse & split routine in place:
var lineNoTable = {},
lines = [],
maxLineNo = 36999;
// parse and split lines to chunks of blobs and line targets
// stores parsed chunks in array lines,
// generates a reference of old and new line numbers in lineNoTable.
function parseSplit() {
var addr = basicStart,
lineNo = startNo,
maxMem = mem.length,
chunks,
blob;
// scans for a jump target,
// generates a target entry and a new blob in current chunks,
// any leading blanks are added to the current blob
function parseLineTarget(maybeList) {
while (mem[addr] === 0x20) {
blob.push(0x20);
addr++;
}
// parse ASCII to string, ignoring any blanks
var n = '',
c = mem[addr];
while ((c >= 0x30 && c <= 0x39) || c === 0x20) {
if (c !== 0x20) n += String.fromCharCode(c);
c = mem[++addr];
}
// if we found a number, push chunks and open a new blob
if (n !== '') {
chunks.push({'type': 'blob', 'val': blob});
chunks.push({'type': 'target', 'val': n});
blob = [];
// scan for any comma (ON GOTO|GOSUB|GO TO)
if (maybeList && c === 0x2C) {
blob.push(0x2C);
addr++;
parseLineTarget(true);
}
}
}
while (addr < maxMem) {
var lineLink = mem[addr++] + (mem[addr++]<<8);
if (!lineLink) break;
chunks = [];
blob = [];
var ln = String(mem[addr++] + (mem[addr++]<<8)),
byte = mem[addr++],
line = {
'ln': ln,
'chunks': chunks
};
lineNoTable[ln] = lineNo;
lineNo += step;
while (byte) {
blob.push(byte);
switch(byte) {
case 0x8F: // REM (read rest of line)
while (mem[addr]) blob.push(mem[addr++]);
break;
case 0x22: // quote (read up to next quote)
var c = mem[addr++];
while (c) {
blob.push(c);
if (c === 0x22) break;
c = mem[addr++];
}
break;
case 0x89: // GOTO
case 0x8D: // GOSUB
parseLineTarget(true);
break;
case 0xA7: // THEN
parseLineTarget(false);
break;
case 0xCB: // GO (read ahead and test for TO)
var t = addr;
while (mem[t] == 0x20) t++; // skip any blanks
if (mem[t] !== 0xA4) break;
while (addr <= t) blob.push(mem[addr++]);
parseLineTarget(true);
break;
}
byte = mem[addr++];
}
if (blob.length) chunks.push({'type': 'blob', 'val': blob});
lines.push(line);
addr = lineLink;
}
}
As this function finishes, we should get a neatly arranged list of lines and chunks, like this:
‘10 …ON A GOTO 1000, 1100’ →
lines = [
{
"ln": 10,
"chunks": [
{
"type": "blob",
"val": […, 0x91, 0x20, 0x41, 0x20, 0x89, 0x20] // …"ON A GOTO "
},
{
"type": "target",
"val": "1000"
},
{
"type": "blob",
"val": [0x2C, 0x20]
},
{
"type": "target",
"val": "1100"
}
]
},
...
]
lineNoTable = {
"10": 100,
...
}
Second Pass — Reassembling the BASIC Code
Reassembling the new code from this should be fairly easy. All we have to do, is joining the chunks, by this replacing old line numbers by new ones. Moreover, we have to generate the linkt to the next line and insert the current line number in binary.
The only tricky part here is the edge case of a dead target line number, for which we do not have an entry in our reference table. What should we do? — Shrug and reuse the old one.
// reassamble BASIC code from line chunks using new line numbers
// from lineNoTable
function reassembleLines() {
var addr = basicStart;
for (var i = 0, max = lines.length; i < max; i++) {
var currLine = lines[i],
currNo = lineNoTable[currLine.ln],
linkAddr = addr;
mem[addr++] = 0;
mem[addr++] = 0;
mem[addr++] = currNo & 0xFF;
mem[addr++] = (currNo >> 8) & 0xFF;
// transfer chunks to memory
for (var j = 0; j < currLine.chunks.length; j++) {
var chunk = currLine.chunks[j];
if (chunk.type === 'blob') {
var blob = chunk.val;
for (var k = 0; k < blob.length; k++)
mem[addr++] = blob[k];
}
else if (chunk.type === 'target') {
var s = '';
if (chunk.val) {
var n = lineNoTable[chunk.val];
s = typeof n !== 'undefined'? n.toString(10):chunk.val;
}
for (var k = 0; k < s.length; k++)
mem[addr++] = s.charCodeAt(k);
}
}
mem[addr++] = 0; //EOL
// fix up the line link
mem[linkAddr++] = addr & 0xFF;
mem[linkAddr] = (addr >> 8) & 0xFF;
}
// end of code (empty line link)
mem[addr++] = 0;
mem[addr++] = 0;
return addr;
}
The new BASIC code is directly injected in the memory slice (mem), which was passed to our function renumberBasic() by reference. Mind that the cursor addr is finally pointing to the first memory location immediately after the reassembled code. Since this may be handy, we pass this as a return value.
Calling the Subroutines
The only thing left is actually calling these functions. Mind that there is an edge case, where the renumbered lines exced the range of valid line numbers. (Compare the value 63999 configured in variable maxLineNo.) Therfore, after calling the function parseSplit(), we should check the highest of the newly assigned line numbers, which happens to be the last entry in lineNoTable. If it is out of range, we abort with an error massage. (On the 6502, we’d probaly call the kernals error routine and output an “ILLEGAL QUANTITY” error.) Otherwise, we call the reassembly routine and return the end address of the newly generated code. Which is also the end of our renumbering routine.
function renumberBasic(mem, basicStart, startNo, step) {
...
parseSplit();
// check, if we are still in the range of legal line numbers
if (lines.length) {
var topLineNo = lineNoTable[lines[lines.length - 1].ln];
// we could throw an exception as well…
if (topLineNo > maxLineNo) return {
'addr': -1,
'message': 'Out of range. Top line number is ' + topLineNo +
' (' + maxLineNo + ' allowed).'
};
}
var endAddr = reassembleLines();
return {
'addr': endAddr
};
}
One Thing Left — Or, What Could Possibly Go Wrong?
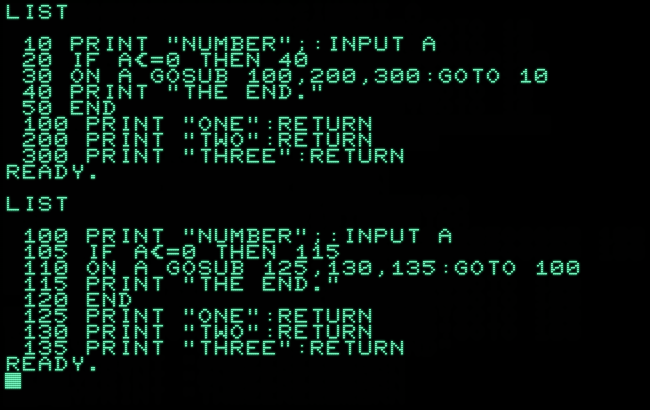
Now, this looks great. If we call our utility routine from the emulator, we should get a nice, renumbered code. Indeed, consider this as simple as pointless test sample (purposefully including some questionable formatting):
10 REM RENUMBER TEST 20 PRINT "NUMBER",:INPUT A 30 IF A<0 THEN 6 0 40 ON A GOTO 100,200, 300 50 GO TO 400 60 GOSUB 500:PRINT "THE END." 70 END 100 PRINT "1 IS A BEGINNING.":GOTO 20 200 PRINT "2 ARE A PAIR.":GOTO 20 300 PRINT "3 ARE A GROUP.":GOTO 20 400 PRINT "MORE THAN 3 ARE A LOT.":GOTO 20 500 PRINT "LESS THAN ZERO IS NOTHING.":RETURN
Calling
renumberBasic(Emulator.getRam(), 0x0401, 100, 10);
and typing “LIST”, we get:
100 REM RENUMBER TEST 110 PRINT "NUMBER",:INPUT A 120 IF A<0 THEN 150 130 ON A GOTO 170,180, 190 140 GO TO 200 150 GOSUB 210:PRINT "THE END." 160 END 170 PRINT "1 IS A BEGINNING.":GOTO 110 180 PRINT "2 ARE A PAIR.":GOTO 110 190 PRINT "3 ARE A GROUP.":GOTO 110 200 PRINT "MORE THAN 3 ARE A LOT.":GOTO 110 210 PRINT "LESS THAN ZERO IS NOTHING.":RETURN
While not particularly intellectual pleasing or challenging, it certainly looks like what we expected. We may even RUN it.
The program even withstands a closer inspection of memory:
0400: 00 15 04 64 00 8F 20 52 ...... R 0408: 45 4E 55 4D 42 45 52 20 ENUMBER 0410: 54 45 53 54 00 29 04 6E TEST.).. 0418: 00 99 20 22 4E 55 4D 42 .. "NUMB 0420: 45 52 22 2C 3A 85 20 41 ER",:. A 0428: 00 39 04 78 00 8B 20 41 .9.... A 0430: B3 30 20 A7 20 31 35 30 .0 . 150 0438: 00 50 04 82 00 91 20 41 .P.... A 0440: 20 89 20 31 37 30 2C 31 . 170,1 0448: 38 30 2C 20 31 39 30 00 80, 190. 0450: 5C 04 8C 00 CB 20 A4 20 \.... . 0458: 32 30 30 00 73 04 96 00 200..... 0460: 8D 20 32 31 30 3A 99 20 . 210:. 0468: 22 54 48 45 20 45 4E 44 "THE END 0470: 2E 22 00 79 04 A0 00 80 ."...... 0478: 00 99 04 AA 00 99 20 22 ...... " 0480: 31 20 49 53 20 41 20 42 1 IS A B 0488: 45 47 49 4E 4E 49 4E 47 EGINNING 0490: 2E 22 3A 89 20 31 31 30 .":. 110 0498: 00 B5 04 B4 00 99 20 22 ...... " 04A0: 32 20 41 52 45 20 41 20 2 ARE A 04A8: 50 41 49 52 2E 22 3A 89 PAIR.":. 04B0: 20 31 31 30 00 D2 04 BE 110.... 04B8: 00 99 20 22 33 20 41 52 .. "3 AR 04C0: 45 20 41 20 47 52 4F 55 E A GROU 04C8: 50 2E 22 3A 89 20 31 31 P.":. 11 04D0: 30 00 F7 04 C8 00 99 20 0...... 04D8: 22 4D 4F 52 45 20 54 48 "MORE TH 04E0: 41 4E 20 33 20 41 52 45 AN 3 ARE 04E8: 20 41 20 4C 4F 54 2E 22 A LOT." 04F0: 3A 89 20 31 31 30 00 1C :. 110.. 04F8: 05 D2 00 99 20 22 4C 45 .... "LE 0500: 53 53 20 54 48 41 4E 20 SS THAN 0508: 5A 45 52 4F 20 49 53 20 ZERO IS 0510: 4E 4F 54 48 49 4E 47 2E NOTHING. 0518: 22 3A 8E 00 00 00 ":....
However, have a look at what the next attempt to list the program looks like, after running the program:
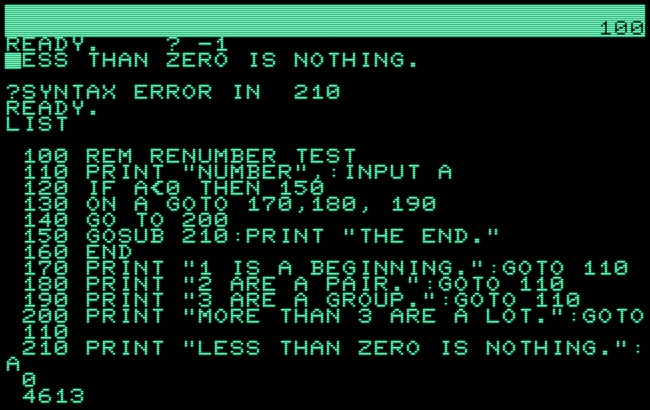
Just look at that mess all over the screen, what is happening here? Are we missing something? Even worse, if we try to edit the program, the editor doesn’t return, as it became lost in some endless loop, apparently! Are we missing something?
Housekeeping — Memory Allocation & BASIC Pointers
Indeed, we are missing something, namely, correct values in the BASIC pointers, which control how BASIC stores and accesses its variables. As our programs grows thanks to longer line numbers in the BASIC text, it also grows into the range of memory, which is used by BASIC for its variables. As a result, the end of our program was overwritten by variables as we ran the program.
Now, what are these pointers and how do they control variable allocation?
These pointers are found in a consecutive area of bytes in the zero page and look like this:
• C64
label loc.hex loc.dec comment
TXTTAB 002B-002C 43-44 Pointer: Start of BASIC Text
VARTAB 002D-002E 45-46 Pointer: Start of BASIC Variables
ARYTAB 002F-0030 47-48 Pointer: Start of BASIC Arrays
STREND 0031-0032 49-50 Pointer: End of BASIC Arrays (+1)
FRETOP 0033-0034 51-52 Pointer: Bottom of String Storage
FRESPC 0035-0036 53-54 Utility String Pointer
MEMSIZ 0037-0038 55-56 Pointer: Highest Address Used by BASIC
• PET 2001 ROM 2.0 ("new ROM") and ROM 4 (BASIC 4.0)
TXTTAB 0028-0029 40-41 Pointer: Start of BASIC Text
VARTAB 002A-002B 42-43 Pointer: Start of BASIC Variables
ARYTAB 002C-002D 44-45 Pointer: Start of BASIC Arrays
STREND 002E-002F 46-47 Pointer: End of BASIC Arrays (+1)
FRETOP 0030-0031 48-49 Pointer: Bottom of String Storage
FRESPC 0032-0033 50-51 Utility String Pointer
MEMSIZ 0034-0035 52-53 Pointer: Highest Address Used by BASIC
• PET 2001 ROM 1.0 ("old ROM")
TXTTAB 007A-007B 122-123 Pointer: Start of BASIC Text
VARTAB 007C-007D 124-125 Pointer: Start of BASIC Variables
ARYTAB 007E-007F 126-127 Pointer: Start of BASIC Arrays
STREND 0080-0081 128-129 Pointer: End of BASIC Arrays (+1)
FRETOP 0082-0083 130-131 Pointer: Bottom of String Storage
FRESPC 0084-0085 132-133 Utility String Pointer
MEMSIZ 0086-0087 134-135 Pointer: Highest Address Used by BASIC
• VIC 20 (same as C64)
TXTTAB 002B-002C 43-44 Pointer: Start of BASIC Text
VARTAB 002D-002E 45-46 Pointer: Start of BASIC Variables
ARYTAB 002F-0030 47-48 Pointer: Start of BASIC Arrays
STREND 0031-0032 49-50 Pointer: End of BASIC Arrays (+1)
FRETOP 0033-0034 51-52 Pointer: Bottom of String Storage
FRESPC 0035-0036 53-54 Utility String Pointer
MEMSIZ 0037-0038 55-56 Pointer: Highest Address Used by BASIC
And this is the meaning of these pointers:
- TXTTAB
- is none other than our old friend, the start of BASIC.
- VARTAB
- is the start of the variable space. It follows immediately after the end of the program in memory (the final empty line-link.) Simple variables are stored here. Each variable occupies 7 bytes of memory, regardless of the type. ARYTAB points to the next available space.
- ARYTAB
- is (also) the beginning of the space allocated for array storage. It points to the location following immediately after the last byte allocated for simple variables.
Note: Since arrays are stored directly above simple variables, adding a new simple variable requires all arrays to be moved in memory in order to provide the required space! - STREND
- is the lower end of the space used for storing string literals. (Strings grow from top to bottom.) This is also the beginning of any free memory, which hasn’t been allocated yet, between the array space and any stored string literals.
- FRETOP
- marks the top end of the unallocated memory, below the last allocated string.
- FRESPC
- is a utility pointer used internally by BASIC. It is not directly involved in variable management, but used for string handling (scratch space, etc).
- MEMSIZ
- is the top address of accessible memory. Strings start growing down from here.
Pointers in Action
Here’s an example for what this looks like in action after running a simple BASIC program (PET 2001, ROM 2.0, 8K RAM: $0000–$1FFF):
• PET 2001 8K, ROM 2.0 ("new ROM")
10 DIM A(10)
20 FOR I=0 TO 10:A(I)=I:NEXT
30 B$=CHR$(66)
→ dump of BASIC prg
0400: 00 0D 04 0A 00 86 20 41 ...... A
0408: 28 31 30 29 00 25 04 14 (10).%..
0410: 00 81 20 49 B2 30 20 A4 .. I.0 .
0418: 20 31 30 3A 41 28 49 29 10:A(I)
0420: B2 49 3A 82 00 32 04 1E .I:..2..
0428: 00 42 24 B2 C7 28 36 36 .B$..(66
0430: 29 00 00 00 )...
→ RUN →
0028: 01 04 ... TXTTAB: $0401
002A: 34 04 ... VARTAB: $0434
002C: 42 04 ... ARYTAB: $0442
002E: 80 04 ... STREND: $0480
0030: FF 1F ... FRETOP: $1FFF
0032: FF 1F ... FRESPC: $1FFF
0034: 00 20 ... MEMSIZ: $2000
→ dump at $0434 (addr in VARTAB):
0434: 49 00 84 30 I..0 real I
0438: 00 00 00 42 80 01 FF 1F ...B.... string B, len. 1 → $1FFF
0440: 00 00 41 00 3E 00 01 00 ..A.>... array A(10)
0448: 0B 00 00 00 00 00 81 00 ........
0450: 00 00 00 82 00 00 00 00 ........
0458: 82 40 00 00 00 83 00 00 .@......
0460: 00 00 83 20 00 00 00 83 ... ....
0468: 40 00 00 00 83 60 00 00 @....`..
0470: 00 84 00 00 00 00 84 10 ........
0478: 00 00 00 84 20 00 00 00 .... ...
0480: AA ........ end of array storage
....
1FF8: AA AA AA AA AA AA AA 42 .......B literal "B"
top of string storage

While this may be still a bit complicated, now have a look at what this pointers look like, just after we load a very simple program without running it:
‘10 PRINT "HELLO WORLD"’
→ loaded into memory, $0401 - $0416
0400: 00 15 04 0A 00 99 20 22 ...... "
0408: 48 45 4C 4C 4F 20 57 4F HELLO WO
0410: 52 4C 44 22 00 00 00 RLD"...
0028: 01 04 ... TXTTAB: $0401
002A: 17 04 ... VARTAB: $0417
002C: 17 04 ... ARYTAB: $0417
002E: 17 04 ... STREND: $0417
0030: 00 20 ... FRETOP: $2000
0032: 00 20 ... FRESPC: $2000
0034: 00 20 ... MEMSIZ: $2000
All, there is, is
TXTTABpointing to the standard start of BASIC,- the address following immediately after the end of program (three times),
- and the top of memory (three times).
This, we easily can provide. (Mind that the address, pointers VARTAB, ARYTAB, STREND are pointing to, is the same address, which our renumbering routine returns.)
Moreover, if our program grew into the variable space in the process of renumbering, any previous data is corrupted anyway. There’s no harm in resetting the pointers to similar (and similarly sane) values as after loading a program. What’s good enough for the Kernal, can’t be totally wrong for us.
Fixing the Pointers
Now that we know this, we may easily adjust the pointers to sane values, like here in this example, where we call our renumbering utility from a function inside the emulator UI (slightly adjusted for the purpose of this write-up):
function renumber() {
// write a 2-byte value to a pointer (lo-byte, hi-byte)
function setPointer(ptrAddr, word) {
Emulator.write(ptrAddr, word & 0xFF);
Emulator.write(ptrAddr + 1, (word >> 8) & 0xFF);
}
var txtTab = Emulator.getRomVers() == 1? 0x7A:0x28, //old or new PET ROM?
mem = Emulator.getRam(),
maxRAM = mem.length,
basicStart = mem[txtTab] | (mem[txtTab + 1] << 8),
result = Utils.renumber(mem, basicStart, startLineNo, step);
endAddr = result.addr;
if (endAddr > 0) {
// success, reset pointers
setPointer(txtTab, basicStart);
setPointer(txtTab + 2, endAddr);
setPointer(txtTab + 4, endAddr);
setPointer(txtTab + 6, endAddr);
setPointer(txtTab + 8, maxRAM);
setPointer(txtTab + 10, maxRAM);
setPointer(txtTab + 12, maxRAM);
}
return result.message;
}
And this is actually all there is. We are finished. We may have even learned some on the way.
(E.g., every time BASIC encounters a new variable, it has to move any arrays in their entirety, as defined as the block of memory between the addresse in pointers ARYTAB and STREND. You may want to optimize your BASIC programs in light of this.)
And we may call our utility in the emulator (see the Utils/Export menu), where we get something like this:
Norbert Landsteiner,
Vienna, 2020-02-27